
- gjenghks@naver.com
- Incheon, South Korea
- Join Research
This research proposes a novel Mutual Knowledge Transfer (MKT) framework for Data-Free Quantization (DFQ), where full-precision (FP) and quantized (Q) models exchange knowledge without original training data. MKT improves previous DFQ techniques by enhancing both layer-wise and class-wise bidirectional knowledge transfer.
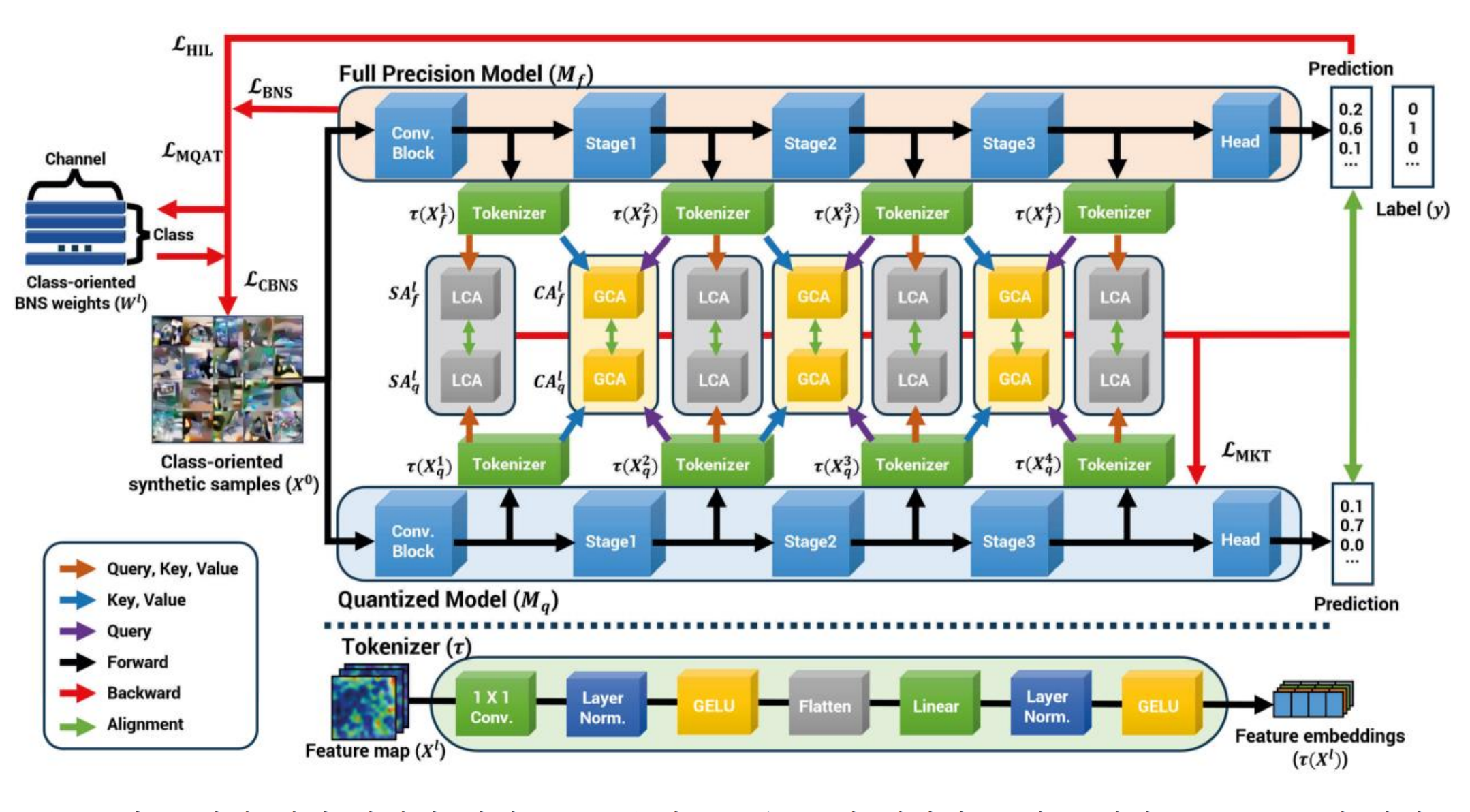
Fig 1. Overall structure of Mutual Knowledge Transfer (source: Paper Figure 1)
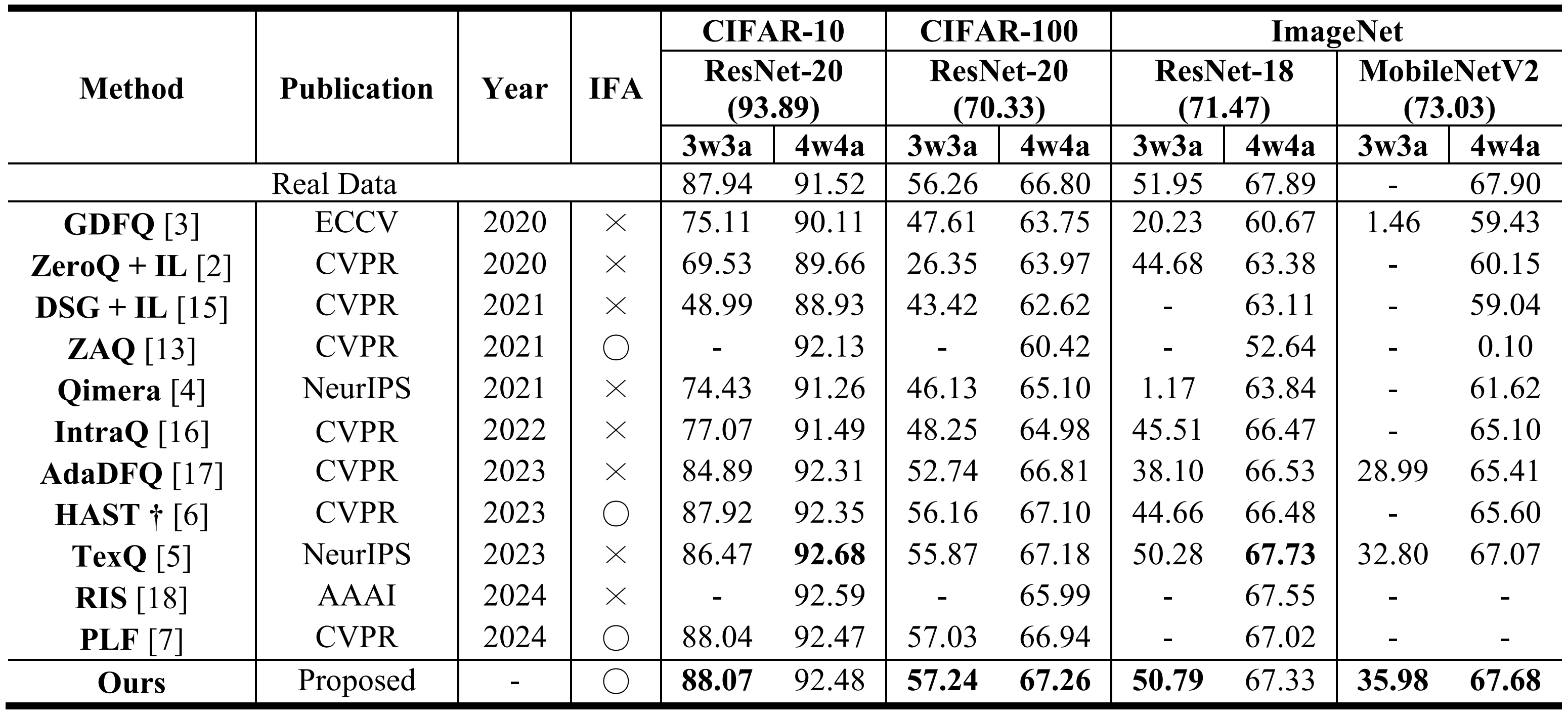
Fig 2. Comparison of MKT with other state-of-the-art DFQ methods (source: Paper Table 1)
MKT outperforms prior DFQ methods like GDFQ, ZeroQ, HAST, and TexQ in CIFAR-10/100 and ImageNet benchmarks—achieving Top-1 accuracy of 57.24% on CIFAR-100 using ResNet-20 at 3w3a quantization, proving its robustness in ultra-low bit settings.